
Table of Contents

Schematron [Schematron] is a structural based validation language, defined by Rick Jelliffe, as an alternative to existing grammar based approaches. Tree patterns, defined as XPath expressions, are used to make assertions, and provide user-centred reports about XML documents. Expressing validation rules using patterns is often easier than defining the same rule using a content model. Tree patterns are collected together to form a Schematron schema.
Schematron is a useful and accessible supplement to other schema languages. The open-source XSLT implementation is based around a core framework which is open for extension and customisation.
This paper introduces the Schematron language and the available implementations. An overview of the architecture, with a view to producing customised versions is also provided.
This paper provides an introduction to Schematron; an innovative XML validation language developed by Rick Jelliffe. This innovation stems from selecting an alternative approach to validation than existing schema languages: Schematron uses a tree pattern based paradigm, rather than the regular grammars used in DTDs and XML schemas. As an extensible, easy to use, open source tool Schematron is an extremely useful addition to the XML developers toolkit.
The initial section of this paper conducts a brief overview of tree pattern validation, and some of the advantages it has in comparison to a regular grammar approach. This is followed by an outline of Schematron and the intended uses which have guided its design. The Schematron language is then discussed, covering all major elements in the language with examples of their usage. A trivial XML vocabulary is introduced for the purposes of generating examples.
The later sections in this paper provides an overview of the open source XSLT framework used to implement the Schematron language. The Schematron conformance language for custom implementation is also introduced. The paper completes with some suggestions of possible future extensions.
The general intent behind this paper is to furnish the reader with a broad overview of both Schematron and its approach to validation. It does not provide a detailed tutorial of the language, although all major elements are discussed, and assumes that the reader is already familiar with XPath, XSLT, and XML DTDs. Other tutorial materials fulfill these roles already [Holman],[XPath],[XSLT] ,[OgbujiC],[OgbujiU].
During the last few years a number of different XML schema languages have appeared as suggested replacements for the ageing Document Type Definition (DTD). The majority of these have taken the basic premise of recasting DTD functionality in XML syntax with the addition, in some cases, of other features such as data typing, inheritance, etc [XMLSchema]. The use of XML syntax provides additional flexibility through leveraging existing tools for markup manipulation, while the 'value added' features satisfy the requirements of developers looking for closer integration with databases and object-oriented languages.
Yet the fundamental approach adopted by these languages does not diverge greatly from the DTD paradigm: the definition of schemas using regular grammars. Less formally, schemas are constructed by defining parent-child and sibling relationships [Jelliffe1999a]. For example in a DTD one might write:
This defines three elements, wall, root, and house. The parent-child relationship between house and wall elements is defined in the content model for house. A house may have several walls.
The sibling relationship between wall and roof is derived from the same content model, which defines them as legal sibling children of the house element.
However this means that DTDs, and similar derivatives, are unable to define (and hence constrain) the other kinds of relationships that exist amongst markup elements within a document. As the XPath specification [XPath] shows, there are many possible kinds of relationship, known as 'axes'.
While XML does include an ID/IDREF mechanism which allows for cross-referencing between elements, and hence another form of relationships, it only weakly binds those elements. There is no enforcement that an IDREF must point to an ID on a particular element type, simply that is must point to an existing ID, and further that all IDs must be unique.
Having highlighted the fact that the existing schema paradigm can only express constraints among data items in terms of the child and sibling axes, it is natural to consider whether an alternate paradigm might allow a schema author to exploit these additional relationships to define additional types of constraint amongst document elements. Tree patterns do just that, and XPath provides a convenient syntax in which to express those patterns.
Validation using tree patterns is a two-step process:
For example, we may select all house nodes within a document using the expression:
And then assert that all houses have walls by confirming that the following pattern selects one or more child nodes (within the context defined by the previous selection):Regular grammars, as used in DTDs, can then be viewed as tree patterns where the only available axis is the parent-child axis [Jelliffe1999e]. Full use of tree pattern validation provides the maximum amount of freedom when modelling constraints for a schema. This comes at very little cost: XPath is available in most XML environments. For example the following types of constraint are hard, or impossible to express with other schema languages.
Tree patterns are the schema paradigm underpinning Schematron as a validation language.
There are reasons to believe that tree-pattern validation may be more suitable in an environment where documents are constructed from elements in several namespaces (often termed 'data islands'). As many consider that the future of XML document interchange on the Internet will involve significant mixing of vocabularies, a flexible approach may bring additional benefits.
Schematron [Schematron] is an XML schema language designed and implemented by Rick Jelliffe at the Academia Sinica Computing Centre, Taiwan. It combines powerful validation capabilities with a simple syntax and implementation framework. Schematron is open source, and is (at the time of writing) being migrated to SourceForge to better manage its development by a rapidly growing community of users.
Schematron traces its ancestry [Jelliffe1999f] indirectly from SGML DTDs via Assertion Grammars [Raggett], Groves and Property Sets [Arciniegas]. A recent review of six current schema languages [Lee] supports this view, declaring Schematron to be unique in both its approach and intent. Before discussing the details of the Schematron language it is worth reviewing the design goals which have been highlighted by its author.
There are several aims which Rick Jelliffe which believed were important during the design and specification of Schematron [Schematron], [Jelliffe2001]:
-
Promote natural language descriptions of validation failures, i.e. diagnose as well as reject
-
Reject the binary valid/invalid distinction which is inherent in other schema languages
-
Aim for a short learning curve by layering on existing tools (XPath and XSLT)
-
Trivial to implement on top of XSLT
-
Provide an architecture which lends itself to GUI development environments
-
Support workflow by providing a system which understands the phases through which a document passes in its lifecycle
Jelliffe has also suggested [Jelliffe2001] several target environments in which Schematron is intended to add value:
-
Document validation in software engineering, through the provision of interlocking constraints
-
Mining data graphs for academic research or information discovery. Constraints may be viewed as hypotheses which are tested against the available data
-
Automatic creation of external markup through the detection of patterns in data, and generation of links
-
Use as a schema language for "hard" markup languages such as RDF.
-
Aid accessibility of documents, by allowing usage constraints to be applied to documents
The implementation of Schematron derives from the observation that tree pattern based validators can be trivially constructed usings XSLT stylesheets [Jelliffe1999b], [Norton]. For example, a simple stylesheet that validates that houses must have walls can be defined as follows:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<!-- select all houses -->
<xsl:template match="//house">
<!-- test whether it has any walls -->
<xsl:if test="not(wall)">
This house has no walls!
</xsl:if>
</xsl:template>
</xsl:stylesheet>
It should be obvious from the above that if a house does not have any walls, a simple error message will be displayed to the user.
Schematron takes this a natural step further by defining a schema language which, when transformed through a meta-stylesheet (i.e. a stylesheet which generates other stylesheets), produces XSLT validators similar to the above. The following diagram summarises this process.
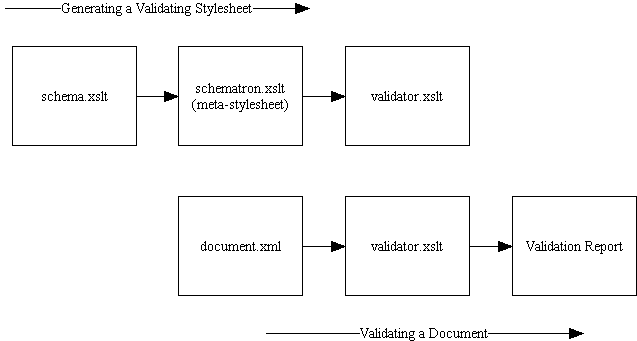
Schematron is therefore a simple layer above XPath and XSLT allowing it to leverage existing tools, and benefit from a framework which is already familiar to XSLT developers. Yet from a user perspective, the details of XSLT are hidden; the end-user need only grapple with the XPath expressions used to define constraints.
The following section outlines the Schematron assertion language which is used to define Schematron schemas. The last section in the paper provides information on the Schematron implementation (i.e. the metastylesheet) which will be of interest to implementors seeking to customise Schematron for particular needs.
This section introduces the Schematron assertion language which can be used to generate XSLT validators using the Schematron implementation. All following examples conform to a simple XML vocabulary introduced in the next section.
The examples used within this section will refer to a fictional XML language for describing building projects. While the examples could have been couched in terms of an existing schema language, the intention is to provide a simple vocabulary which does not assume any prior knowledge on behalf of the user. It should be stressed that, while the examples themselves may be trivial this should not be taken to indicate any specific limitation in Schematron, which is capable of handling much more complex schemas.
The following DTD defines the building project vocabulary:
Example 3. Simple XML language for illustrative purposes
<!ELEMENT wall EMPTY/>
<!ELEMENT roof EMPTY/>
<!ELEMENT street #PCDATA>
<!ELEMENT town #PCDATA>
<!ELEMENT postcode #PCDATA>
<!ELEMENT firstname #PCDATA>
<!ELEMENT lastname #PCDATA>
<!ELEMENT certification EMPTY>
<!ATTLIST certification number CDATA #REQUIRED>
<!ELEMENT telephone #PCDATA>
<!ELEMENT address (street, town, postcode)>
<!ELEMENT builder (firstname, lastname, certification)>
<!ELEMENT owner (firstname, lastname, telephone)>
<!ELEMENT house (wall+, roof?, address, (builder|owner)?>
This schema allows us to describe a house consisting of a number of walls and a roof. The roof may not be present if the house is still under construction.
A house has an address which consists of a street name, town and a postcode.
A house should have either a builder who is currently assigned to its construction (and all builders must be certified), or an owner. Certification numbers of builders, and telephone numbers of owners are also recorded for adminstrative purposes.
A sample document instance conforming to this schema is:
The basic building blocks of the schematron language are the assert and report elements. These define the constraints which collectively form the basis of a Schematron schema. Constraints are assertions (boolean tests) that are made about patterns in an XML document; these patterns and tests are defined using XPath expressions.
The best illustration is a simple example:
<assert test="count(walls) = 4">This house does not have four walls</assert>
If there are not four walls then the assertion fails and a message, the content of the assert element, is displayed to the user.
Asserts therefore operate in the conventional way: if the assertion evaluates to false some action is taken. The report element works in the opposite manner. If the test in a report element evaluates to true then action is taken.
While reports and asserts are effectively the inverse of one another, the intended uses of the two elements are quite different. An assert is used to test whether a document conforms to a particular schema, generating actions if deviations are encountered. A report is used to highlight features of the underlying data:
The distinction may seem subtle, especially when grapplying with a constraint which may be expressed simpler in one way or the other. However Schematron itself does not define the action which must be taken on a failed assert, or successful report, this is implementation specific. The default behaviour is to simply provide the user with the provided message. An implementation may choose to handle these two cases differently.It is worth noting that there is a trade-off to be made when defining tests on these elements. In some cases a single complex XPath expression may accurately capture the desired constraint. Yet it is closer to the 'spirit' of Schematron's design to use several smaller tests that collectively describe the same constraint. Specific tests can more accurately provide feedback to a user, than a single general test and associated message.
Assert and Report elements may contain a name element which has an optional path attribute. This element will be substituted with the name of the current element before a message is passed to the user. When supplied the path attribute should contain an XPath expression referencing an alternate element. This is useful for giving additional feedback to the user about the specific element that failing an assertion.
Schematron 1.5, released in January 2001, adds the ability to provide detailed diagnostic information to users. Assert and report messages should be simple declarative statements of what is, or should be. Diagnostics can include detailed information that can be provided to the user as appropriate to the Schematron implementation. Diagnostic information is grouped separately to constraints, and is cross-referenced from a diagnostic attribute.
As noted earlier, constraints must be applied within a context. The context for constraints is defined by grouping them together to form rules.
Example 8. Defining the context for assertions
<rule context="house">
<assert test="count(wall) = 4">A house should have four walls</assert>
<report test="not(roof)">This house does not have a roof</assert>
</rule>
The context attribute for a rule contains an XPath expression. This identifies the candidate nodes to which constraints will be applied. The above example checks that a house contains 4 wall child elements, and provides feedback to the user if it is missing a roof.
Schematron 1.5 add a simple macro mechanism for rules which is useful when combining constraints. To do this, a rule may be declared as 'abstract'. The contents of this rule may be included by other rules as necessary. This is achieved through the use of the extends element.
Example 9. Using abstract rules and the extends element
<rule abstract="true" id="nameChecks">
<assert test="firstname">A person must have a first name</assert>
<assert test="lastname">A person must have a last name</assert>
</rule>
<rule context="builder">
<extends rule="nameChecks"/>
<!-- builder specific constraints -->
...
</rule>
<rule context="owner">
<extends rule="nameChecks"/
<!-- owner specific constraints -->
...
</rule>
In the above example an abstract rule is defined, and assigned the id "nameChecks". Two assertions are associated with this abstract rule: checking that an element has a firstname and a lastname. These assertions are imported by the other non-abstract rules and will be applied along with the other constraints specific to that element. An abstract rule may contain assert and report elements but it cannot have a context. Assertions from an abstract rule obtain their context from the importing rule.
The next most important element in a Schematron schema is pattern. Patterns gather together a related set of rules. A particular schema may include several patterns that logically group the constraints.
Example 10. Grouping rules using patterns
<pattern name="Adminstration Checks"
see="http://www.buildingprojects.org/admin/procedures.html">
<rule abstract="true" id="nameChecks">
<assert test="firstname">A person must have a first name</assert>
<assert test="lastname">A person must have a last name</assert>
</rule>
<rule context="builder">
<extends rules="nameChecks"/>
<!-- builder specific constraints -->
...
</rule>
<!-- additional rules -->
...
</pattern>
<pattern name="Other Constraints">
<!-- other rules -->
</pattern>
A pattern should have a name and may refer to additional documentation using a URL. A Schematron implementation can then furnish the user with a link to supporting documentation.
Patterns defined within a schema will be applied sequentially (in lexical order). Nodes in the input document are then matched against the contexts defined by the rules contained within each pattern. If a node is found to match the context of a particular rule, then the assertions which it contains will be applied. Within a pattern a given node can only be matched against a single rule. Rules within separate patterns may match the same node, but only the first match within a pattern will be applied. An example of an incorrect schema is given below.
Example 11. Incorrect use of rule contexts
<pattern name="Adminstration Checks">
<!-- this rule WILL be matched -->
<rule context="builder">
<assert test="firstname">A person must have a first name</assert>
</rule>
<!-- this rule WILL NEVER be matched -->
<rule context="builder">
<assert test="lastname">A person must have a last name</assert>
</rule>
<!-- additional rules -->
...
</pattern>
<!-- rules in this pattern will be checked after the above -->
<pattern name="Other Constraints">
<!-- this rule WILL be matched -->
<rule context="builder">
<assert test="certification">A builder must be certified</assert>
</rule>
<!-- additional rules -->
...
</pattern>
Care should be taken when defining contexts to ensure that these circumstances never arise.
The last step in defining a Schematron schema is to wrap everything up in a schema element.
Example 12. Grouping patterns to create a schema
<schema xmlns="http://www.ascc.net/xml/schematron">
<title>A Schematron Schema for Validating Building Project Documents</title>
<ns uri="http://www.buildingprojects.org/admin/" prefix="bld"/>
<pattern name="Adminstration Checks">
<!-- rules -->
</pattern>
<pattern name="Construction Checks">
<!-- rules -->
</pattern>
</schema>
There are several points to note about the above schema. Firstly it introduces the namespace for Schematron documents, which is "http://www.ascc.net/xml/schematron". Secondly a schema may have a title; this is recommended.
A Schematron design goal is the support of workflow. Schematron achieves this using the concept of phases. A phase allows constraints to be applied according to the state of a document within its lifecycle.
A Schematron schema may define any number of phases, where a phase involves the processing of one or more patterns. This means that constraints will be applied selectively according to the active phase. Identifying the active phase is an implementation specific mechanism, but may be accomplished through command-line arguments to the XSLT engine. A schema may define a default phase which will be selected if not overridden.
<sch:schema xmlns:sch="http://www.ascc.net/xml/schematron"
defaultPhase="built">
<sch:phase id="underConstruction">
<sch:active pattern="construction"/>
<sch:active pattern="admin">
</sch:phase>
<sch:phase id="built">
<sch:active pattern="completed"/>
<sch:active pattern="admind"/>
</sch:phase>
<sch:pattern name="Construction Checks" id="construction">
<!-- check for four walls, and an assigned builder -->
</sch:pattern>
<sch:pattern name="Final Checks" id="completed">
<!-- check the house has a roof, and has an owner -->
</sch:pattern>
<sch:pattern name="Adminstration Checks" id="admin">
<!-- check postal codes, addresses, etc -->
</sch:pattern>
</sch:schema>
In the above example two phases are defined for our example XML documents. The first phase is "underConstruction", and captures constraints that need to be checked when a house is being built. This involves checks that the architectural plans are being followed (there are four walls!) and that a builder has been assigned. The second phase ("built") captures constraints that are to be enforced once construction is completed. These check that a roof has been put on, and that the house now has an owner.
Notice that the default phase is defined by an attribute on the schema element, and that each pattern has an identifier. This identifier is referenced from active elements within the individual phases. The "Construction Checks" constraints are only applied in the "underConstruction" phase, while the "Adminstration Checks" are performed in both phases. An individual phase may contain any number of active patterns. By default all patterns within a schema are active, e.g. if there are no phases defined.
Phases provide a dynamic approach to validation that not only allows different constraints to be applied at different times, but also the possibility that individual patterns may be switched on and off as desired. In other schema languages the only way to accomodate this kind of phased validation is to either loosen the schema constraints (to accept the lowest common denominator), or to use multiple schemas which individually capture the constraints for a particular status [Jelliffe1999c].
It is easy to envisage a GUI interface for Schematron that allows a user to select the individual patterns they wish to apply to a document. This is useful in authoring environments when a document may temporarily exist in an invalid state [Jelliffe1999d], but the user wishes to check that certain aspects, for example the tables in an XHTML document, are correct.
This section includes a complete sample Schematron schema for the example building projects schema introduced earlier. The sample schema introduces a few additional elements from the Schematron language not covered in previous sections. These are simple documentation elements to markup paragraphs, etc. which functional identically to their XHTML equivalents. Additional details on these elements can be found in [Jelliffe2001] and [Zvon].
Example 14. A Complete Sample Schema
<sch:schema xmlns:sch="http://www.ascc.net/xml/schematron"
icon="http://www.ascc.net/xml/resource/schematron/bilby.jpg"
defaultPhase="built">
<sch:p>This is an example schema for the <emph>Building Projects XML</emph> language.</sch:p>
<sch:phase id="underConstruction">
<sch:active pattern="construction"></sch:active>
<sch:active pattern="admin"></sch:active>
</sch:phase>
<sch:phase id="built">
<sch:active pattern="completed">completed</sch:active>
<sch:active pattern="admin">admin</sch:active>
</sch:phase>
<sch:pattern name="Construction Checks" id="construction">
<sch:p>Constraints which are applied during construction</sch:p>
<sch:rule context="house">
<sch:assert test="count(wall) = 4">A house should have 4 walls</sch:assert>
<sch:report test="not(roof)">The house is incomplete, it still needs a roof</sch:report>
<sch:assert test="builder">An incomplete house must have
a builder assigned to it</sch:assert>
<sch:assert test="not(owner)">An incomplete house cannot have an owner</sch:assert>
</sch:rule>
</sch:pattern>
<sch:pattern name="Final Checks" id="completed">
<sch:p>Constraints which are applied after construction</sch:p>
<sch:rule context="house">
<sch:assert test="count(wall) = 4">A house should have 4 walls</sch:assert>
<sch:report test="roof">The house is incomplete, it still needs a roof</sch:report>
<sch:assert test="owner">An incomplete house must have
an owner</sch:assert>
<sch:assert test="not(builder)">An incomplete house doesn't need a builder</sch:assert>
</sch:rule>
</sch:pattern>
<sch:pattern name="Adminstration Checks" id="admin">
<sch:p>Adminstrative constraints which are <sch:emph>always</sch:emph> applied</sch:p>
<sch:rule context="house">
<sch:assert test="address">A house must have an address</sch:assert>
</sch:rule>
<sch:rule context="address">
<sch:assert test="count(*) = count(street) + count(town) + count(postcode)">
An address may only include street, town and postcode elements.
</sch:assert>
<sch:assert test="street">An address must include the street details</sch:assert>
<sch:assert test="town">An address must identify the town</sch:assert>
<sch:assert test="postcode">An address must have a postcode</sch:assert>
</sch:rule>
<sch:rule abstract="true" id="nameChecks">
<sch:assert test="firstname">A <name/> element must have a first name</sch:assert>
<sch:assert test="lastname">A <name/> element must have a last name</sch:assert>
</sch:rule>
<sch:rule context="builder">
<sch:extends rule="nameChecks"></sch:extends>
<sch:assert test="certification">A <name/> must be certified</sch:assert>
</sch:rule>
<sch:rule context="owner">
<sch:extends rule="nameChecks"></sch:extends>
<sch:assert test="telephone">An <name/> must have a telephone</sch:assert>
</sch:rule>
<sch:rule context="certification">
<sch:assert test="@number">Certification numbers must be recorded
in the number attribute</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
The following sections provide an overview of the XSLT framework which forms the basic architecture for Schematron. Some guidance is given on producing custom implementations and experimental versions of the Schematron language. The conformance language is also introduced. The section ends with some notes on possible future extensions.
As Figure 1 shows, Schematron is implemented as a meta-stylesheet which is used to generate a validating stylesheet. The mapping of the assertion language to XSLT templates and functions is quite trivial.
Table 1. Mapping Core Schematron Elements into XSLT
| Schematron | XSLT |
|---|---|
Assert
<sch:assert test="...">...</sch:assert> |
Choose
<xsl:choose> <xsl:when test="..."/> <xsl:otherwise>...</xsl:otherwise> </xsl:choose> |
Report
<sch:report test="...">...</sch:report> |
If
<xsl:if test="..."> ... </xsl:if> |
Rule
<sch:rule context="..."> ... </sch:rule> |
Template
<xsl:template match="..." mode="..." priority="..."> ... </xsl:template> |
Pattern
<sch:pattern name="..."> ... </sch:pattern> |
Apply-Templates
<xsl:apply-templates select="/" mode="..."/> |
| N/A | Root Template
<xsl:template match="/"> ... </xsl:template> |
The above table demonstrates that the assert and report elements map very simply onto XSLT control blocks. Rules are mapped onto individual XSLT templates whose match pattern is taken directly from the context specified by the rule. All rules defined within a single pattern share the same mode, and are invoked from an xsl:apply-templates element which specifies this mode. A single xsl:apply-templates is generated for each pattern contained in the schema. Other Schematron elements are similarly mapped into XSLT elements and/or functions.
Validators generated by the base Schematron stylesheet produce plain text messages for the user as a result of failed asserts, and successful reports. It is possible to enhance this by deriving a custom implementation from the base stylesheet.
The Schematron framework follows a design pattern often referred to in object-oriented circles as the "Hollywood Pattern" (Don't call us, we'll call you...). Essentially this means that the basic framework provides a number of hooks which an implementor can use to attach their own custom code. These hooks are then invoked automatically by the framework, which retains control of the processing.
These hooks are provided invoking a number of named templates whilst transforming a Schematron schema into an validating stylesheet. In most cases default versions of these templates are provided in the framework, but these can be overridden when importing the base stylesheet into a custom implementation [XSLT]. The following table provides a summary of the main extension hooks.
Table 2. Summary of Main Extension Hooks in the Schematron Framework
| Template Name | Usage |
|---|---|
| process-prolog | Invoked once at the start of the transformation. Custom implementations may override this to add elements to the 'prolog' of the generated stylesheet. Useful for adding additional xsl:import and xsl:variable declarations, etc. |
| process-root | Invoked once at the start of the transformation. Custom implementations may override this to customise the root template in the generated stylesheet. By default this will simply contain one xsl:apply-templates element for each pattern. |
| process-assert | Invoked once for every assert matched in the schema. The default implementation simply invokes the process-message template (see below). |
| process-report | Invoked once for every report matched in the schema. The default implementation simply invokes the process-message template (see below). |
| process-pattern | Invoked once for every pattern in the schema. The default implementation does nothing. |
| process-rule | Invoked once for every rule in the schema. The default implementation does nothing. |
| process-message | Invoked by the process-assert and process-report templates. The default implementation simply outputs the normalised content of the element. E.g. the message contained within an assert element. Useful to override when the custom implementation wishes to treat asserts and reports identically |
This table is not an exhaustive list of all the possible extension points. There are hooks available for most elements in the Schematron language, although the majority of extensions will involve using the above templates. Many of these templates are invoked with a number of parameters derived from attributes on the originating element. For example the process-assert template is invoked with several parameters including the value of the assert's test attribute, etc.
A simple example of an custom implementation is provided below. This implementation simply wraps up the Schematron output as HTML to further pretty-print the output.
Example 15. Trivial Example of a Custom Schematron Implementation
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<!-- import the basic framework -->
<xsl:import href="schematron.xsl"/>
<!-- override the process-root template and wrap output as HTML -->
<xsl:template name="process-root">
<xsl:param name="title"/>
<xsl:param name="contents" />
<html>
<head><title>Validation Report For: <xsl:value-of select="$title"/></title></head>
<body>
<h1>Validation Report For : <xsl:value-of select="$title"/></h1>
<pre>
<xsl:copy-of select="$contents" />
</pre>
</body>
</html>
</xsl:template>
<!-- override additional templates as needed -->
</xsl:stylesheet>
Interested developers may wish to explore ways of extending the Schematron language itself. Again, this can be achieved through extensions to the basic framework. New language elements should be defined in their own namespace to clearly mark them as additions. Additional templates to match and process these language extensions can then be added to a custom implementation.
To ensure interoperability between Schematron implementations the latest version adds a simple conformance language [Conformance] that can be used as the basis for producing test suites. The conformance language captures the desired output of a Schematron validator as a series of 'events'. A failed assert is an event, as is a successful report.
Rick Jelliffe has produced an extension to the base Schematron framework which generates validators whose output is a conformance language document. This means that given a schema and a sample input document the output of the validation process can be captured in a canonical form. The same schema, input document, and the generated output can be used to test whether a second Schematron implementation produces the same output.
A sample conformance language document is provided below.
Example 16. Sample Conformance Language Document
<schematron-output xmlns:sch="http://www.ascc.net/xml/schematron"
title="" schemaVersion="" phase="not implemented">
<active-pattern name="Final Checks"/>
<fired-rule id="" context="house" role=""/>
<failed-assert id="" test="owner" role="" location="/house[1]">
<text>An incomplete house must have an owner</text>
</failed-assert>
<failed-assert id="" test="not(builder)" role="" location="/house[1]">
<text>An incomplete house doesn't need a builder</text>
</failed-assert>
<active-pattern name="Adminstration Checks"/>
<fired-rule id="" context="house" role=""/>
<fired-rule id="" context="address" role=""/>
<fired-rule id="" context="builder" role=""/>
<fired-rule id="" context="certification" role=""/>
</schematron-output>
The conformance language will prove useful in ensuring interoperability between implementations. While XSLT is the target implementation platform for Schematron, there is nothing to stop a Java implementation from being constructed if suitable XPath libraries are available. A Perl version of Schematron has already been implemented.
The current target XSLT engine for Schematron is XT, to ensure that it is compatible with the widest range of processors. This does limit the implementation to the facilities that XT supports: at present XT does not support keys() for example.
Given the extensibility of Schematron and its ease of integration with existing XML tools, it is worth considering some possible future directions.
The XML-DEV mailing list has recently begun [Dodds] a project to define an XML vocabulary for describing the range of resources that can be associated with an XML Namespace. Resource Discovery Description Language [RDDL] is an extension of XHTML Basic [XHTML] meaning that while it lists resources in a machine processable form, RDDL documents are also human-readable. It would be interesting to extend Schematron to make it 'RDDL-aware'.
RDDL documents are intended to be placed at the URL associated with an XML Namespace [XMLNames]. In theory it should be possible to allow Schematron to retrieve these documents during validation and check whether other, Namespace-specific validators are available. If so, then these validators could also be invoked. In essence this would allow Schematron to accept an input document consisting of elements from a number of Namespaces and then retrieve additional schemata automatically from the Internet.
While Schematron does not provide much support for data types beyond basic strings, nodes and numbers [Jelliffe2000], it is possible to simulate additional types [Lee] using the available mechanisms. For example constraints can be expressed that check allowed ranges for numbers, or confirm that attribute and element content conforms to an enumerated set of values. Use of the XPath document() function even allows checking of enumerated values contained in an external document (which may itself dynamically generated on request).
Fundamentally though data types are not a first class entity in the Schematron language. However data type manipulation and checking could be added to Schematron through use of the standard XSLT extension functions. A potentially useful exercise would be to define a set of useful 'business' functions which perform more complex type checking. Of course if knowledge of data types were added to XPath then Schematron would inherit this directly. Indeed any additions to XPath and XSLT should immediately benefit Schematron due to its simple layering.
A noted design goal is to allow Schematron to be easily implemented within a GUI environment, e.g. an XML IDE. Patterns, asserts, and reports may all have associated icons, and detailed help messages can be provided using the diagnostics elements. The ability to activate and deactivate individual patterns within a schema has already been highlighted as a useful feature in authoring environments.
It would be interesting project to implement a user interface that exploits these features. It may be that an existing XML IDE incorporating scripting and/or XSLT support may provide an framework for this development. Those XSLT engines which provide emacs and/or vi style line numbers in their xsl:message output will be particularly useful in this regard, allowing users to jump directly to the origin of a given validation message.
An existing example is schematron-report, a custom schematron extension that generates a two-pane HTML report as its output. The validation output is contained in one frame, while the original markup is displayed in the other. Validation messages are directly linked to elements in the original markup.
Tree pattern based validation has already been characterised as a two step process of identification and then assertion. Currently Schematron relies on XPath to express both steps. However there are projects which currently exploring the definition of a query language for XML documents. When these projects bear fruit it may be possible to use such a language as a substitute for XPath in the identification of candidate objects for validation.
While there may be no direct benefits for validation applications, in the realm of data mining and automated markup generation (both target uses for Schematron) there may be many advantages.
Schematron is unique amongst current schema languages in its divergence from the regular grammar paradigm, and its user-centric approach.
Schematron is not meant as a replacement for other schema languages; it is not expected to be easily mappable onto database schemas or programming language constructs. It is a simple, easy to learn language that can perform useful functions in addition to other tools in the XML developers toolkit.
It is also a tool with little overhead, both in terms of its learning curve and its requirements. XSLT engines are regular components in any XML application framework. Schematrons use of XPath and XSLT make it instantly familiar to XML developers.
A significant advantage of Schematron is the ability to quickly produce schemas that can be used to enforce house style rules and, more importantly, accessibility guidelines without alteration to the schema to which a document conforms. An XHTML document is still an XHTML document even if it does not meet the Web Accessibility Initiative Guidelines [WAI]. These kind of constraints describe a policy which is to be enforced on a document, and can thus be layered above other schema languages. Indeed in many cases it may be impossible for other languages to test these kinds of constraints.
Bibliography
[Arciniegas] 19/04/2000. Groves Explained .
[Conformance] Schematron Conformance Language .
[Dodds] 10/1/2001. Old Ghosts: XML Namespaces .
[Jelliffe1999a] 1999. From Grammars To The Schematron .
[Jelliffe1999b] 24/01/1999. Using XSL as a Validation Language .
[Jelliffe1999c] 11/06/1999. How to Promote Organic Plurality on the WWW .
[Jelliffe1999d] 30/07/1999. Weak Validation .
[Jelliffe1999e] 01/08/1999. Axis Models & Path Models: Extending DTDs with XPaths .
[Jelliffe1999f] 1999. Family Tree of Schema Languages for Markup Languages .
[Jelliffe2000] 19/10/2000. Getting Information Into Markup: the Data Model Behind the Schematron Assertion Language .
[Jelliffe2001] 31/1/2001. The Schematron Assertion Language 1.5 .
[Norton] 20/5/1999. Generating XSL for Schema Validation .
[OgbujiC] Validating XML with Schematron .
[OgbujiU] Introducing the Schematron .
[Quick] Schematron Quick Reference .
[Raggett] May 1999. Assertion Grammars .
[RDDL] 22/1/2001. Resource Directory Description Language .
[Schematron] Schematron Home Page .
[WAI] 5/5/1999. Web Content Accessibility Guidelines 1.0 .
[XHTML] 19/12/2000. XHTML Basic .
[XMLNames] 14/1/1999. Namespaces in XML .
[XMLSchema] 24/10/2000. XML Schema Part 0: Primer .
[XPath] November 1999. XML Path Language (XPath) Version 1.0 .
[XSLT] James Clark. November 1999. XML Transformations (XSLT) Version 1.0 .
[Zvon] Zvon Schematron Tutorial .