Much of the recent evolution of the web has been centred on data: data publishing, data exchanges, mashing up and recombining data, and access management of personal and enterprise data that spans both business and social networks.
As this evolution continues the volume of data on the web will only continue to increase. We have barely begun to scratch the surface with regards to data publishing. The tools and environments that we currently use to manage, share and publish data will need a complete overhaul and sustained innovation in order to let us easily take advantage of this data deluge.In Web 2.0 we focused primarily on "mashing up" data sources. This involved taking often disparate, but usually related, datasets and combining them to create interesting and compelling visualisations. While the availability of web APIs enabled easier access to data, allowing developers and enthusiasts access to information that was previously hard to either acquire or manipulate, creation of anything beyond the most trivial mash-ups (combining RSS feeds, creating mapping overlays) required a skilled programmer.
The semantic web community often refers to "mesh-ups": mash-ups that are created from Linked Data. By using Linked Data the act of combining datasets is often much easier. The shared underlying data model (RDF) makes the merging of datasets much simpler: the linking together of data ("meshing") from different sources is typically already a part of the source datasets, allowing application code to easily traverse the web of data (or locally mirrored subsets) to find and query relevant material.
A mash-up involves taking data, with very different data structures, and coercing it into a common model for a particular application to consume. The results, while often compelling, are typically a new data silo: the merged data often exists only inside the internal data structures of the mash-up application where it cannot be reused.
In contrast, mesh-ups typically draw on data that is in the same or similar models. At the very least the data conforms to a basic graph model that can be easily imported and exported from RDF databases. Mesh-ups usually involve creating and publishing new relationships, making the graph easier to traverse. Re-publishing of those links thereby adds to the overall web of data. Mesh-ups therefore provide utility outside of the scope of the original visualisation or presentation of the data. The skills and expertise of the programmer creating the mesh-up can be shared in the form of additional open data, not just a user interface.
The general trend in computing is away from low-level procedural programming languages and towards declarative tool-kits that provide useful abstractions. Abstraction provides scope for optimisation and standardisation, but most importantly it provides a means to create simpler tools that allow domain experts rather than software engineers to apply their expertise to the job of creating and sharing value.
Today's mesh-ups provide a hint of how data manipulation tools may evolve, and suggest useful abstractions that could provide domain experts with the ability to more easily contribute to value creation.
Whether creating a mash-up or a mesh-up, the same basic process is involved:
Currently domain experts are largely involved in the creation of the underlying data sets, or consulted during the analysis, whereas the remaining steps are typically carried out by a software engineer. Through convergence on useful abstractions, including standardised data access and visualisation mechanisms, this process could be made much simpler and more accessible.
But what are those abstractions?
Linked Data alone is not the answer to this question. Linked Data provides a principled way to publish data onto the web, encourages a standard model and representations for data, and provides standard technologies (HTTP, SPARQL) for accessing that data. But it doesn't provide a high-level abstraction for manipulating datasets.
What is needed is an abstraction for describing how to manipulate and combine data in aggregate.
One way to think about this is to consider the process of aggregating or combining data as one of "layering" together a number of smaller datasets, each of which contributes a particular type of data to the mix.
There are a number of different generic types of dataset. For any given resource - a car, a research article, a person, or an event - there are a number of different possible facets to the data items associated with it. Setting aside for a moment the mechanics of how these data items are represented in a data model, we can lay out the following candidate facets:
Not all of these different data facets are relevant for all types of resource. And while for some resources the values of these data facets may be fixed, for others the values may vary over time. But regardless of the specific domain or application model, the same basic data facets re-occur across all kinds of different datasets.
| Facet | Person | Article | Place |
|---|---|---|---|
| Factual | Name | Title | Name |
| Commentary | Mentions | Comments, Reviews | Discussion |
| Comparative | Leader-board | Popularity | Popularity |
| Network | Social network | References, citations | Twinning |
| Organisational | Ethnicity | Subject | Type of Place |
| Structural | - | Part Of | Spatial Calculus |
| Positional | Geographic Co-ordinates, Birth date | Publication date | Geographic Co-ordinates |
If we look at successful Web 2.0 services in the light of this simple faceting scheme, then what we see is a trend towards the creation of simple, focused services that specialise in the management of one particular type of data facet. Typically backed by a social curation model (crowd-sourcing).
These services are actually creating a dataset that is primarily organised around a particular type of data facet, often focused on resources from a specific subject domain. A mash-up or mesh-up typically combines several data facets from across separate services by querying and merging data in application code.
The opportunity for innovation lies in the creation of tools that allow whole datasets to be manipulated more easily, shifting focus away from service integration and towards a higher level abstraction: the data layer.
A data layer is either a whole dataset or a useful subset. The layer contains data that is organised around a particular type of data facet, e.g. comparative or factual data. By layering datasets together, rather than mashing them up, we abstract away the detail of service integration, relying on a common data model (RDF) to handle much of the effort in data merging.
Graph based data models are particularly appropriate to this kind of abstraction as they support both the inclusion of a variety of different data types, whilst also including a strong notion of identity and linking. Strong identifiers are a critical part of this abstraction. However it is not critical that identifiers have to be globally agreed: identifiers gain value when they are adopted and annotated by a community.
Application code can manipulate the aggregate data as if it were a single data set. But, importantly, the individual data layers are preserved as separate entities, allowing new layers to be easily added and alternative layers to be easily substituted into the mix. This means the provenance of each layer remains intact, allowing domain experts to more easily choose between higher and lower quality datasets. In so doing we have the potential to easily switch between different providers of a particular type of data layer, or simply aggregate all of the trusted sources we can find.
A typical mash-up or mesh-up can be re-imagined as a presentation or visualisation lens that fronts a layered database assembled from a number of different, specialised sources.
The following diagram illustrates the creation of an aggregated dataset by layering together data of different types.
The dataset below is made up of several factual sources, a network layer that defines relationships between those sources, as well as commentary and organisational data that provide context to some resources in the dataset.
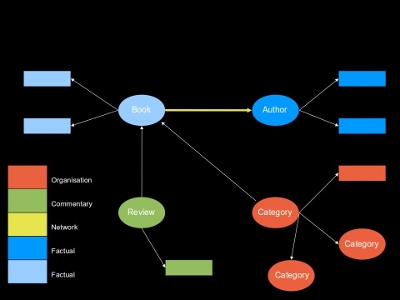
A collection of layers can be viewed "in profile", providing insight into how a collection of data layers have been "stacked" together. The collection can be viewed "top down" in order to explore and query the data as a graph.
A separate PDF document provides an illustration of how a dataset can be composed from several source showing both the profile and top-down views.
Opportunities exist to create a marketplace to support the creation, publishing and purchasing of data layers. Tools can be provided to manipulate data layers, and services can be bound to individual data layers or composite datasets to support query and data extraction via web and mobile applications.
With the ability for domain experts to easily combine data from different sources, it will be much easier not just to combine datasets, but also to compare the value of different datasets. This encourages data providers to compete on the quality of data that they are publishing. And, by focusing on the need to provide just additional value-added data – in order to enrich data available from other sources – data providers can focus their curation efforts on a much smaller set of data. This reduces costs by eliminating the need for maintaining redundant copies of data. Annotation will be an important model within such a marketplace.
Aggregation and re-aggregation of data by the composition of data sets through layering of different sources will greatly reduce the effort in pulling together data from a wide variety of different sources. This reduction in effort, coupled with the ability to easily deploy web APIs against that combined data, will allow a more rapid and cost effective approach to the creation of large-scale data-driven applications.
A marketplace for data layers will provide small businesses and domain experts with the ability to turn their expertise into direct value by allowing them to select and arrange data layers to create high value aggregates and services that can be directly monetized.